










@InProceedings{serifi2026hypergaussians,
author = {Serifi, Gent and Buehler, Marcel C.},
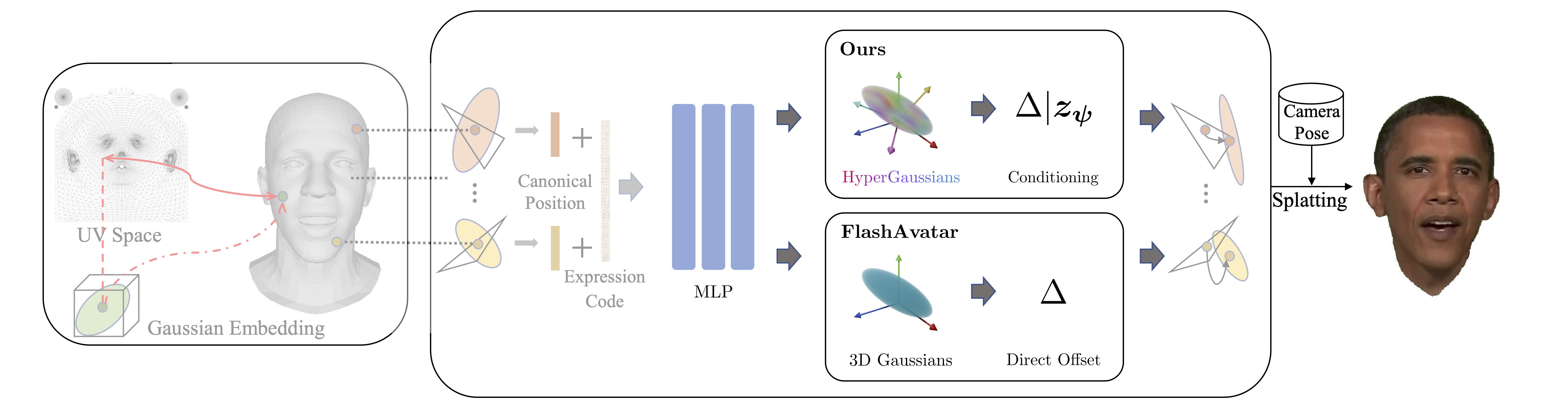
title = {HyperGaussians: High-Dimensional Gaussian Splatting for High-Fidelity Animatable Face Avatars},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {25236-25247}
}